Source: Microservices and Biological Systems
Microservices and Biological Systems

In 2010, several researchers at Yale attempted to look at biological systems versus computer software design. As would be expected, biological systems, which evolved over millions of years, are much more complex, have a considerable amount of redundancy and lack a direct top-down control architecture as found in software like the Linux kernel1. While these comparisons aren’t entirely fair, considering the complexity of biology2, they are a fun thought experiment. Microservices are a new-emergent phenomenon in the software engineering world, and in many ways, microservice architectures evolve in environments that are much closer to a biological model than that of carefully architected, top-down approaches to monolithic software.
In 2007, I was introduced to the concept of Service Orientated Architecture. The general concept around SOA is that in a large company where you had a lot of teams and data, departments who were the source of record for certain types of data would also provide services to access and modify that data. This initially took the form of just having shared libraries, but eventually evolved to network services, often web services, using SOAP as their transport. At least, that was the idea in concept, but in reality, often many different teams would write similar services for the same parts of the database and have direct access to a lot of the same data stores. Some teams would open services up to others, and services would require multiple versions to be maintained concurrently in order to transition from one version to another. This lead to a system that was complex, coupled in odd ways that it probably shouldn’t have been, and could lead an organization into the current era of microservices.
“…So here’s a graph of [Uber’s] service growth. You’ll note it doesn’t end at a thousand, even though I said a thousand. This is because we don’t have a reliable way of sorta tracking this over time. It’s like bizarre, but it’s somehow really hard to get the exact number of services that are running in production at any one time because it’s changing so rapidly. There are all these different teams who are building all these different things and they’re cranking out new services every week. Some of the services are going away, but honestly, tracking the total count is like this sort of weird anomaly … it’s sort of not a thing people care about.” -Matt Ranney, GOTO 20163
The speed at which software engineers can write and deploy services has grown significantly in the last couple of years. It is still possible to quickly write a lot of bad software (services without unit tests, committed without code reviews, and riddled with security issues, that contribute to technical debt). However, it’s also become easier to develop well written software, with good test coverage and continuous integration pipelines. In a mid to large sized company, this can cause rapid growth in many interdependent services, tooling pipelines and 3rd party integrations.
Environments where microservices start to thrive are much more akin to biological processes. The traditional waterfall approach requires that components be laid out in a linear fashion, often with rigorous design documentation, with each component being completed and tested before dependent tasks can begin. This type of process was essential to ensuring quality and minimizing delays.
Back in the era of AS/400s and mainframe computers, small mistakes were not easy to undo, and could lead to delays of tens of thousands of man hours and millions of dollars. Even today, hardware still needs to meet strict requirements. In 1994, the Pentium FDIV bug, which affected floating point math, lead to a recall with an estimated cost of $475 million USD4. In more recent years, Intel has been hit by numerous security concerns over side-channel attacks including Spectre and Meltdown. Mitigating these attacks in software can lead to considerable performance issues in some workloads5. In the world of physical engineering, adhering to strict approaches, and heavily testing any new approaches, is essential. Any oversight can be potentially disastrous, such as with the 2018 bridge collapse at the Florida International University-Sweetwater6, or the ongoing grounding of the Boeing 737-MAX 8.
There is a lot of software today that is written for business cases and non-critical systems. Software outages and failures could lead to a loss of money or convenience for some, but people won’t die if they can’t reach Instagram or YouTube for a day (although I’m some people wouldn’t shut up about it, and become incredibly annoying to be around). These are the types of environments where microservices tend to incubate, grow and thrive.
From the Ground Up
Microservices tend to be built around things. Products can be built at different speeds throughout a company. It’s not uncommon for a service to handle multiple versions of a given message schema, in order to be ready for the time when other teams can transition. Political motivations and pet projects are things that microservices usually work around, but they can also be used to introduce new technologies without interfering with current workflows. Sometimes services provide a level of redundancy, or at the very least, immutability. Some teams choose to never change a service once it’s deployed; instead simply deploying a new version and telling everyone to get off the old one. If a bad service loads two million records incorrectly, a team can often fix the service and re-queue messages in order to back-fill the data.
“Everything’s a tradeoff … You might choose to build a new service, instead of fixing something that’s broken … that doesn’t maybe seem like a cost at first … maybe that seems like a feature. I don’t have to wade into that old code and risk breaking it. But at some point the costs of always building around problems and never cleaning up the old problems … starts to be a factor. And another way to say that is, you might trade complexity for politics … instead of having to have a maybe awkward conversation with some other human beings … this is really easy to avoid if you can just write more software…that’s a weird property of this system…“ -Matt Ranney, GOTO 20163
It’s not that microservices can’t be built to be resilient, but in an environment filled with services, where everything is now a remote procedure call into a complex system, they have to be built well. Resiliency, handling bad data and monitoring all must be built into each service in order for the entirety of the business process to be reliable.
In all these situations, microservices evolved around systems that are developed very quickly. They tend to grow from breaking down larger monolithic applications into their core components. You should never start with microservice. In a company where a newly hired principal engineer comes in from a microservice shop, they may tend to immediately build small modules in individual repository with empty stubs everywhere. This is a terrible idea.
You should always start with a monolith. Ensure that it is well tested, well designed and developed with several iterations from the core developers. Trying to start with microservices will lead to changes needing to be merged into dependent projects, in order to increment a version number, just so those features are available for downstream projects. It turns into a fragile mess of empty stubs, missing documentation, and inconsistent projects, instead of the strong independent (yet potentially redundant) series of systems that come from a more natural evolution of software development.
Caveat
I want to make the disclaimer that I’m not equivocating the complexity in microservices to actual biological systems. I’m simply using biology to the measure it was used in the aforementioned PNAS paper, which made comparisons between cell regulation and the monolithic Linux Kernel1. In Ierymenko’s article on artificial intelligence, he makes the argument that neurons can’t be modeled as simple circuits or closed-form equations2. The following image shows the gene regulatory network diagram from e. coli (left), a literal poop microbe. Compare that to a partial human cell’s gene regulatory network (right) which is important for understanding variability in cancer7.
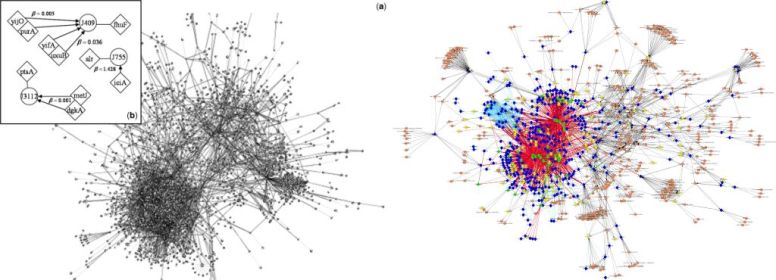
Actual biological systems are insanely complex. For decades we’ve barely scratched the surface on understanding gene regulatory systems. In this context, the comparison I’m showing simply makes for a fun, and hopefully useful, analogy.
Conclusions
Microservices can be done right, or rather, after systems evolve at an organization, some teams can have really good, well thought out services, with large numbers of unit and integration tests. Yet, they are still the ultimate product of an often weird evolutionary process, that tends to be muddled with technical debt, company policies, legal requirements and politics. People who try to start with a microservice model are asking for a world of pain and hurt. Good microservices come from using the foundation of well written monoliths as a template for splitting out and creating smaller components. You don’t build a city out of molecules. You have several layers of abstraction in place so you can build with bricks, structures and buildings.
Critical software is like building a bridge, where engineers attempt to think out each component and their integrations in their entirety. Mistakes in the software of someone’s pacemaker, or in the safety system of a vehicle, are bugs that literally can never be recovered from. In contrast, biological organisms tend to have static and unchanging components that preform a discrete set of tasks. Although susceptible to random mutations, the individual parts of an organism are vying for the best fitness in a given environment.
Microservices are more akin to biological evolution, often more resilient to change and inconsistency, and built to handle interference from the outside world. But like biological organisms, they are also complex, susceptible to environmental changes, disease and outside factors that can cause them to fail. Like a degenerative disease or cancer, they may have failures that propagate slowly or silently, in ways that are incredibly difficult to track down, diagnose and fix.
- Comparing genomes to computer operating systems in terms of the topology and evolution of their regulatory control networks. 18 May 2010. Yan, Fang, Bhardwaj, Alexander and Gerstein. PNAS. ↩ ↩2
- On the Imminence and Danger of AI. 16 March 2015. Ierymenko. (Archived) ↩ ↩2
- GOTO 2016 • What I Wish I Had Known Before Scaling Uber to 1000 Services • Matt Ranney. 28 Sept 2016. Ranney. Goto; 2016. (Video) ↩ ↩2
- Pentium PDIV flaw FAQ. 19 August 2011. Nicely. (E-mail / Archived) ↩
- Meltdown and Spectre. 2018. Graz University of Technology. Retrieved 23 December 2019. ↩
- The Ordinary Engineering Behind the Horrifying Florida Bridge Collapse. 16 March 2018. Marshall. Wired. ↩
- Vast New Regulatory Network Discovered in Mammalian Cells. 14 Oct 2011. Bioquick News. ↩
